Celestia's data availability layer
Celestia is a data availability (DA) layer that provides a scalable solution to the data availability problem. Due to the permissionless nature of the blockchain networks, a DA layer must provide a mechanism for the execution and settlement layers to check in a trust-minimized way whether transaction data is indeed available.
Two key features of Celestia's DA layer are data availability sampling (DAS) and Namespaced Merkle trees (NMTs). Both features are novel blockchain scaling solutions: DAS enables light nodes to verify data availability without needing to download an entire block; NMTs enable execution and settlement layers on Celestia to download transactions that are only relevant to them.
Data availability sampling (DAS)
In general, light nodes download only block headers that contain commitments (i.e., Merkle roots) of the block data (i.e., the list of transactions).
To make DAS possible, Celestia uses a 2-dimensional Reed-Solomon encoding scheme to encode the block data: every block data is split into
Then,
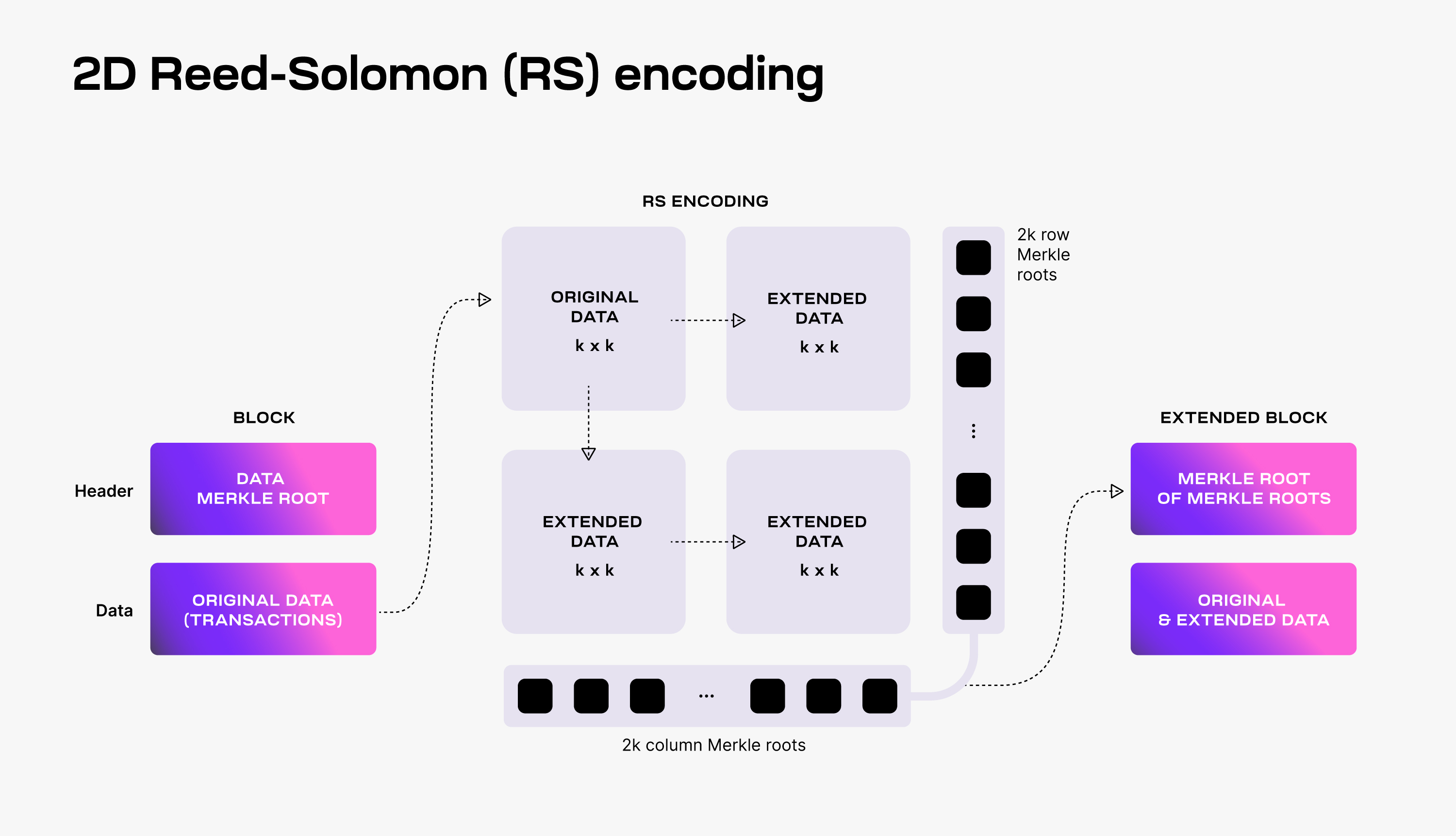
To verify that the data is available, Celestia light nodes are sampling the
Every light node randomly chooses a set of unique coordinates in the extended matrix and queries full nodes for the data shares and the corresponding Merkle proofs at those coordinates. If light nodes receive a valid response for each sampling query, then there is a high probability guarantee that the whole block's data is available.
Additionally, every received data share with a correct Merkle proof is gossiped to the network. As a result, as long as the Celestia light nodes are sampling together enough data shares (i.e., at least
For more details on DAS, take a look at the original paper.
Scalability
DAS enables Celestia to scale the DA layer. DAS can be performed by resource-limited light nodes since each light node only samples a small portion of the block data. The more light nodes there are in the network, the more data they can collectively download and store.
This means that increasing the number of light nodes performing DAS allows for larger blocks (i.e., with more transactions), while still keeping DAS feasible for resource-limited light nodes. However, in order to validate block headers, Celestia light nodes need to download the
For a block data size of
Fraud proofs of incorrectly extended data
The requirement of downloading the
The downside of the standard Reed-Solomon encoding is dealing with malicious block producers that generate the extended data incorrectly.
This is possible as Celestia does not require a majority of the consensus (i.e., block producers) to be honest to guarantee data availability. Thus, if the extended data is invalid, the original data might not be recoverable, even if the light nodes are sampling sufficient unique shares (i.e., at least
As a solution, Fraud Proofs of Incorrectly Generated Extended Data enable light nodes to reject blocks with invalid extended data. Such proofs require reconstructing the encoding and verifying the mismatch. With standard Reed-Solomon encoding, this entails downloading the original data, i.e.,
Namespaced Merkle trees (NMTs)
Celestia partitions the block data into multiple namespaces, one for every application (e.g., rollup) using the DA layer. As a result, every application needs to download only its own data and can ignore the data of other applications.
For this to work, the DA layer must be able to prove that the provided data is complete, i.e., all the data for a given namespace is returned. To this end, Celestia is using Namespaced Merkle trees (NMTs).
An NMT is a Merkle tree with the leafs ordered by the namespace identifiers and the hash function modified so that every node in the tree includes the range of namespaces of all its descendants. The following figure shows an example of an NMT with height three (i.e., eight data shares). The data is partitioned into three namespaces.
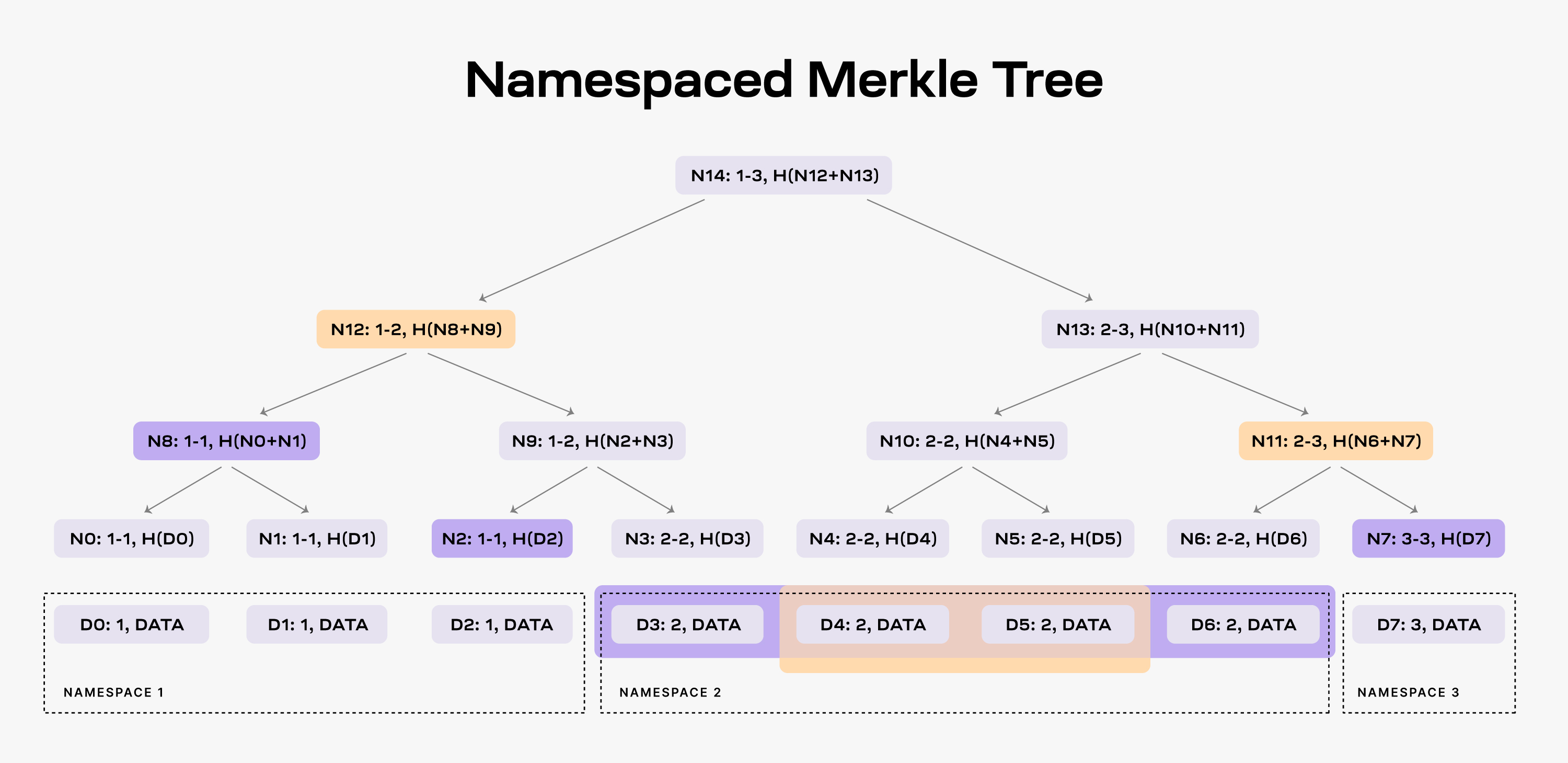
When an application requests the data for namespace 2, the DA layer must provide the data shares D3, D4, D5, and D6 and the nodes N2, N8 and N7 as proof (note that the application already has the root N14 from the block header).
As a result, the application is able to check that the provided data is part of the block data. Furthermore, the application can verify that all the data for namespace 2 was provided. If the DA layer provides for example only the data shares D4 and D5, it must also provide nodes N12 and N11 as proofs. However, the application can identify that the data is incomplete by checking the namespace range of the two nodes, i.e., both N12 and N11 have descendants part of namespace 2.
For more details on NMTs, refer to the original paper.
Building a PoS blockchain for DA
Providing data availability
The Celestia DA layer consists of a PoS blockchain. Celestia is dubbing this blockchain as the celestia-app, an application that provides transactions to facilitate the DA layer and is built using Cosmos SDK. The following figure shows the main components of celestia-app.
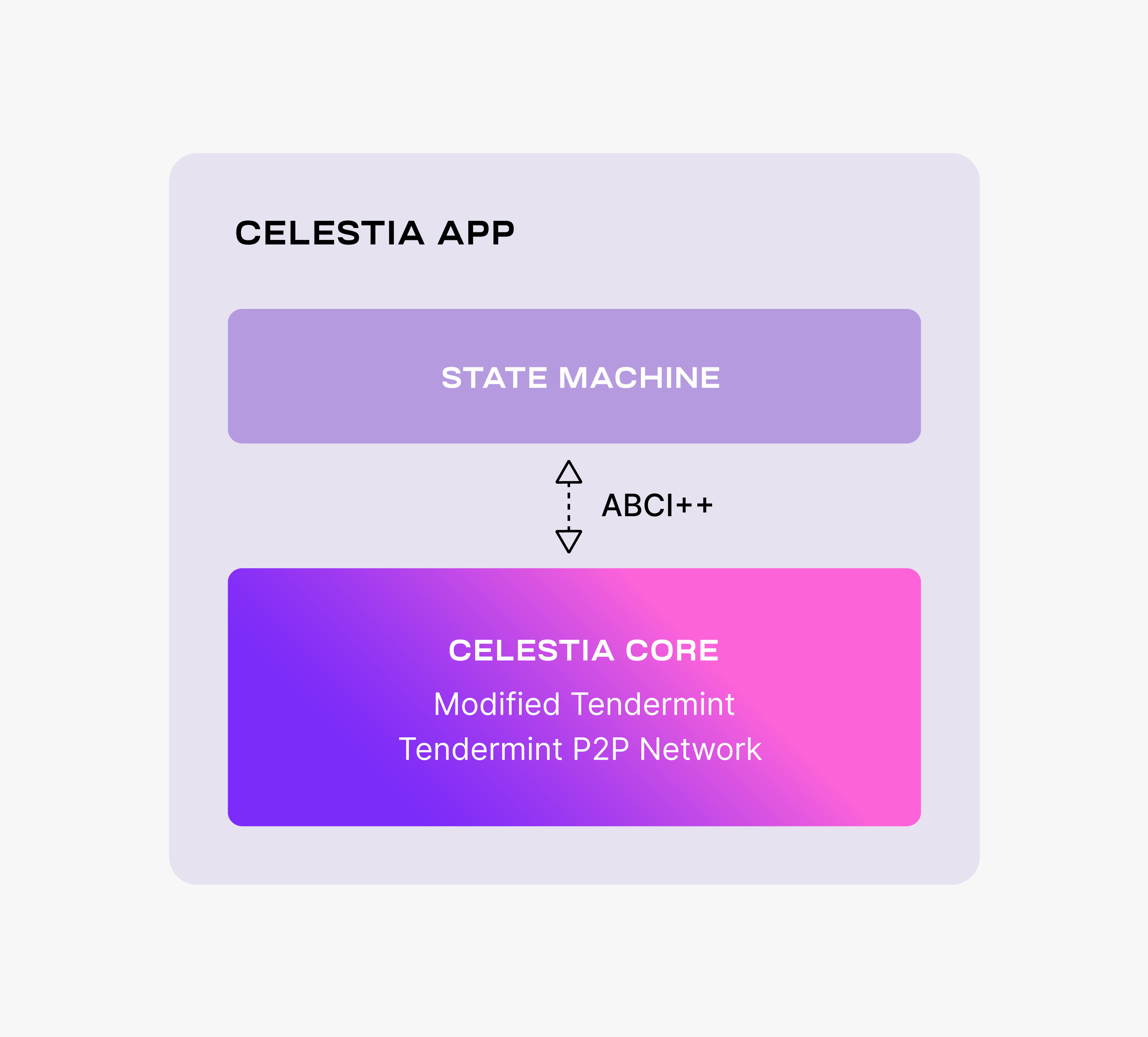
celestia-app is built on top of celestia-core, a modified version of the Tendermint consensus algorithm. Among the more important changes to vanilla Tendermint, celestia-core:
- Enables the erasure coding of block data (using the 2-dimensional Reed-Solomon encoding scheme).
- Replaces the regular Merkle tree used by Tendermint to store block data with a Namespaced Merkle tree that enables the above layers (i.e., execution and settlement) to only download the needed data (for more details, see the section below describing use cases).
For more details on the changes to Tendermint, take a look at the ADRs. Notice that celestia-core nodes are still using the Tendermint p2p network.
Similarly to Tendermint, celestia-core is connected to the application layer (i.e., the state machine) by ABCI++, a major evolution of ABCI (Application Blockchain Interface).
The celestia-app state machine is necessary to execute the PoS logic and to enable the governance of the DA layer.
However, the celestia-app is data-agnostic -- the state machine neither validates nor stores the data that is made available by the celestia-app.